
- 开云体育(中国)官方网站获南向资金增握的有4天-开云kaiyun登录入口登录APP下载(中国)官方网
- 本站音问,10月10日南向资金增握3700.0股迈富时(02556.HK)。近5个来回日中开云体育(中国)官方网站,获南向资金增握的有4天,累计净增握2200....

开yun体育网
大年月朔,阿里发出大模子新年第一弹。
1月29日凌晨1点半,阿里云通义千问旗舰版模子Qwen2.5-Max老成升级发布。据其先容,Qwen2.5-Max模子是阿里云通义团队对MoE模子的最新探索后果,预考试数据卓绝20万亿tokens,展现出极强劲的笼统性能,在多项公开主流模子评测基准上录得高分,全面超越了当今全球起原的开源MoE模子以及最大的开源粘稠模子。
与Qwen2.5-Max进行对比的模子,就包括了最近火爆海表里的DeepSeek旗下的V3模子。受新模子的影响,阿里巴巴好意思股拉升,一度涨超7%,收盘录得6.71%的涨幅,报96.03好意思元/股。

最近几天,DeepSeek冲击了好意思股的投资逻辑,导致英伟达等巨头股价大幅震撼。
据央视新闻音讯,当地时代1月28日,好意思国多名官员回复DeepSeek对好意思国的影响,暗示DeepSeek是“偷窃”,正对其影响开展国度安全观看。
就在前一天,好意思国总统特朗普还称DeepSeek是很积极的技巧后果。
不管是在硅谷、华尔街及白宫掀翻山地风云的DeepSeek,照旧阿里通义千问新发布的大模子,国产大模子最近的密集革命后果标明,中国东说念主工智能的跳跃与追逐,一经极猛进度篡改了全球AI的行业模式。
阿里新模子性能全球起原
阿里通义千问团队暗示,Qwen2.5-Max接管超大范畴MoE(混杂行家)架构,基于卓绝20万亿token的预考试数据及全心接头的后考试决策进行考试。
据先容,Qwen2.5-Max在常识、编程、全面评估笼统才能的以及东说念主类偏好对皆等主流泰斗基准测试上,展现出全球起原的模子性能。领导模子是总共东说念主可径直对话体验到的模子版块,在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等基准测试中,Qwen2.5-Max并排Claude-3.5-Sonnet,并险些全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
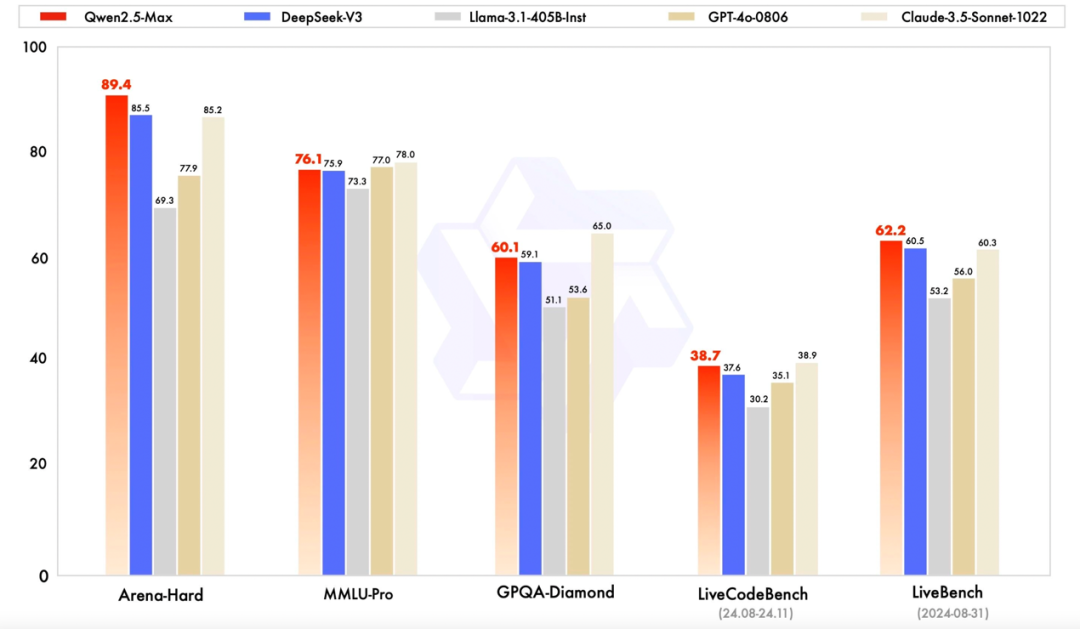
同期,基座模子反应模子裸性能,由于无法拜访GPT-4o和Claude-3.5-Sonnet等闭源模子的基座模子,通义团队将Qwen2.5-Max与当今起原的开源MoE模子DeepSeek V3、最大的开源粘稠模子Llama-3.1-405B,以及相通位列开源粘稠模子前方的Qwen2.5-72B进行了对比。截止自大,在总共11项基准测试中,Qwen2.5-Max一齐超越了对比模子。
记者还审视到,除了发布Qwen2.5-Max除外,1月28日,阿里还开源了全新的视觉和会模子Qwen2.5-VL,推出了3B、7B、72B三个尺寸版块。其中,旗舰版Qwen2.5-VL-72B在13项泰斗评测中夺得视觉和会冠军,全面超越GPT-4o与Claude3.5。
阿里巴巴股价走势
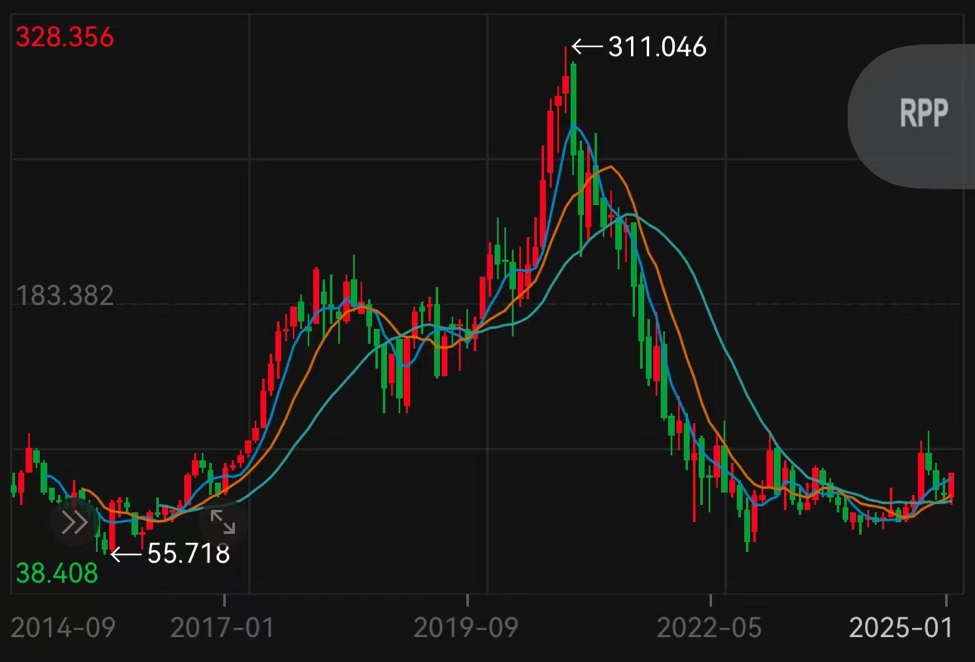
受新模子的影响,阿里巴巴好意思股拉升,一度涨超7%,收盘录得6.71%的涨幅,报96.03好意思元/股。Qwen2.5-Max的发布激发了成本商场对于重估中国AI金钱的接头。如果将阿里巴巴好意思股上市后的股价走势时代轴拉长,其股价在2020年摸到311.046好意思元的高位后,便进入了下行的通说念。业内东说念主士分析,阿里云不仅发布了与全球顶尖模子并排以致更优的模子,何况具备完好的云生态,或能酿成肖似客岁北好意思云筹画干事商的投资逻辑。
DeepSeek除外,大厂大模子也值得关心
最近几天,全球的注眼光都在DeepSeek上,但有国内头部大模子厂商的中枢技巧主干告诉证券时报记者,包括阿里通义千问、字节豆包、腾讯混元在内的互联网大厂大模子才能其实并不差,仅仅DeepSeek当作创业公司,和互联网大厂在发展策略上有所不同。DeepSeek当作纯技巧启动的公司,代码和考试关节澈底开源,而互联网大厂通常出于交易化等方面的考量不会澈底开源。
“DeepSeek出圈的原因主要照旧跟金融商场关连。从基座才能上看,其实莫得那么强,对咱们的冲击也莫得那么大。”该技巧主干告诉记者,好意思国股市高潮的逻辑主若是AI和英伟达芯片,但DeepSeek让东说念主们发现可能不需要这样多英伟达的卡,就能作念出来性能差未几的模子。“何况还开源了,是以DeepSeek才这样受关心。”该技巧主干暗示。
与此同期,DeepSeek主若是在文本生成才能和和会才能方面比拟强,尤其擅长汉文语境下的长文本和复杂语境,DeepSeek V3和R1暂无多模态生成才能。有行业从业者向记者暗示,以豆包等为代表的大厂模子都属于多模态大模子,在大言语模子基础上和会了图片、音频、视频等多种模态,对算力底座条款更高,不仅要补助大范畴考试任务,还要确保端侧诳骗的及时性和高效性。
因此,DeepSeek除了通过革命架构与优化算法裁汰考试成本外,还能愈加聚焦于大言语模子界限。别称国内大模子高管在分析DeepSeek的到手时就指出,有相对充裕的卡(算力资源),莫得融资压力,前边几年只作念模子不作念家具,这些都让DeepSeek愈加隧说念和聚焦,大要在工程技巧和算法上有所冲破。
前述国内头部大模子厂商的中枢技巧主干还露馅,1月22日字节发布的豆包大模子1.5Pro,在多个测评基准上起原于很多头部的模子,“咱们的压力不来自于DeepSeek,而是豆包,仅仅豆包1.5Pro莫得出圈,全球没审视到。”该技巧主干说。
DeepSeek濒临“蒸馏”争议
记者审视到,字节筹商团队还暗示,豆包1.5Pro通过高效标注团队与模子自普及相市欢的状貌抓续优化数据质地,严格革职里面圭臬,不使用任何其他模子的数据,确保数据来源的平安性和可靠性,也即莫得通过“蒸馏”其他模子来走捷径。
所谓“蒸馏”,指的是一种开荒者用来优化微型模子的关节,是一种在深度学习和机器学习界限世俗诳骗的技巧,通俗和会等于用事前考试好的复杂模子输出的截止,当作监督信号再去考试另外一个通俗的模子。这样不错大幅减少筹画资源消费,让小模子在特定任务中以低成本获得肖似效果。
DeepSeek的技巧文档暗示,R1模子使用了数据蒸馏技巧(Distillation)生成的高质地数据普及了考试效用。周二,白宫东说念主工智能和加密货币事务负责东说念主大卫.萨克斯在接管该媒体采访时声称,DeepSeek“有可能”窃取了好意思国的常识产权才得以崛起。他还暗示,异日几个月好意思国起原的东说念主工智能公司将选用门径,试图防患“蒸馏”。据金融时报报说念,OpenAI称它发现DeepSeek使用了OpenAI专有模子来考试我方的开源模子的凭证,但远隔进一步露馅其凭证的细节。
不外多名业内东说念主士暗示,“蒸馏”固然存在一定争议,但其实是大模子考试中一种常用的关节。由于考试复杂模子需要参加宽敞资源,并雇用专科东说念主员指导模子如何生成合乎东说念主类抒发状貌的回答,耗钱耗时代,而“蒸馏”则不错幸免这个问题。因此,不管是在中国照旧好意思国,初创公司和学术机构使用ChatGPT等具有东说念主类反馈优化的交易大言语模子输出数据来考试我方的模子,被视为一种宽敞的、“默而不宣”的风光。
由中国科学院深圳先进技巧筹商院、北大等机构齐集髻表的论文《大言语模子的蒸馏量化》中开yun体育网,筹商者就提到除了Claude、豆包和Gemini之外,刻下有名的开闭源大言语模子均进展出了较高的“蒸馏”水平。筹商东说念主员宽敞以为,“蒸馏”大要使模子考试的效用更好、成本更低,但会使模子的特有性下落,且过度“蒸馏”也会导致模子性能下落。